Gene-level QC and differential expression (DESeq2)
Last updated on 2026-06-16 | Edit this page
Estimated time: 85 minutes
Overview
Questions
- How do we explore RNA seq count data before running DESeq2.
- How do we restrict analysis to protein coding genes.
- How do we perform differential expression with DESeq2.
- How do we visualize sample relationships and DE genes.
- How do we save a useful DE results table with annotation and expression values.
Objectives
- Import count and sample metadata into R.
- Attach biotype and gene symbol annotation to Ensembl gene IDs.
- Explore library sizes, variance stabilizing transforms, distances, and PCA.
- Run DESeq2 for a two group comparison.
- Create a volcano plot with gene symbols.
- Export joined DE results including normalized counts and annotation.
Introduction
In this episode we move from count matrices to differential expression analysis and visualization.
The workflow has four parts:
- Import counts and sample metadata.
- Exploratory analysis on protein coding genes (quality checks).
- Differential expression analysis with DESeq2.
- Visualization and export of annotated DE results.
What you need for this episode
-
gene_counts_clean.txtgenerated from featureCounts - a
samples.csvfile describing the experimental groups - RStudio session on Scholar using Open OnDemand
While we created the count matrix in the previous episode, we still
need to create a sample metadata file. This file should contain at least
two columns: sample names matching the count matrix column names, and
the experimental condition (e.g., control vs treatment). Simply
copy/paste the following into a text file and save it in your
scripts directory as samples.csv:
sample,condition
WT_Bcell_mock_rep1,WT_mock
WT_Bcell_mock_rep2,WT_mock
WT_Bcell_mock_rep3,WT_mock
WT_Bcell_mock_rep4,WT_mock
WT_Bcell_IR_rep1,WT_IR
WT_Bcell_IR_rep2,WT_IR
WT_Bcell_IR_rep3,WT_IR
WT_Bcell_IR_rep4,WT_IRAlso, create a direcotry for DESeq2 results:
All analyses are performed in R through Open OnDemand
Step 1: Start Open OnDemand R session and prepare data
We will be using the OOD to start an interactive session on Scholar: https://gateway.negishi.rcac.purdue.edu
- Login using your Purdue credentials after clicking the above link
- Click on “Interactive Apps” in the top menu, and select “RStudio (Bioconductor)”
- Fill the job submission form as follows:
- queue:
rcac-rnaseq - Walltime:
4 - Number of cores:
4
- queue:
- Click “Launch” and wait for the RStudio session to start
- Once the session starts, you’ll will be able to click on “Connect to RStudio server” which will open the RStudio interface.
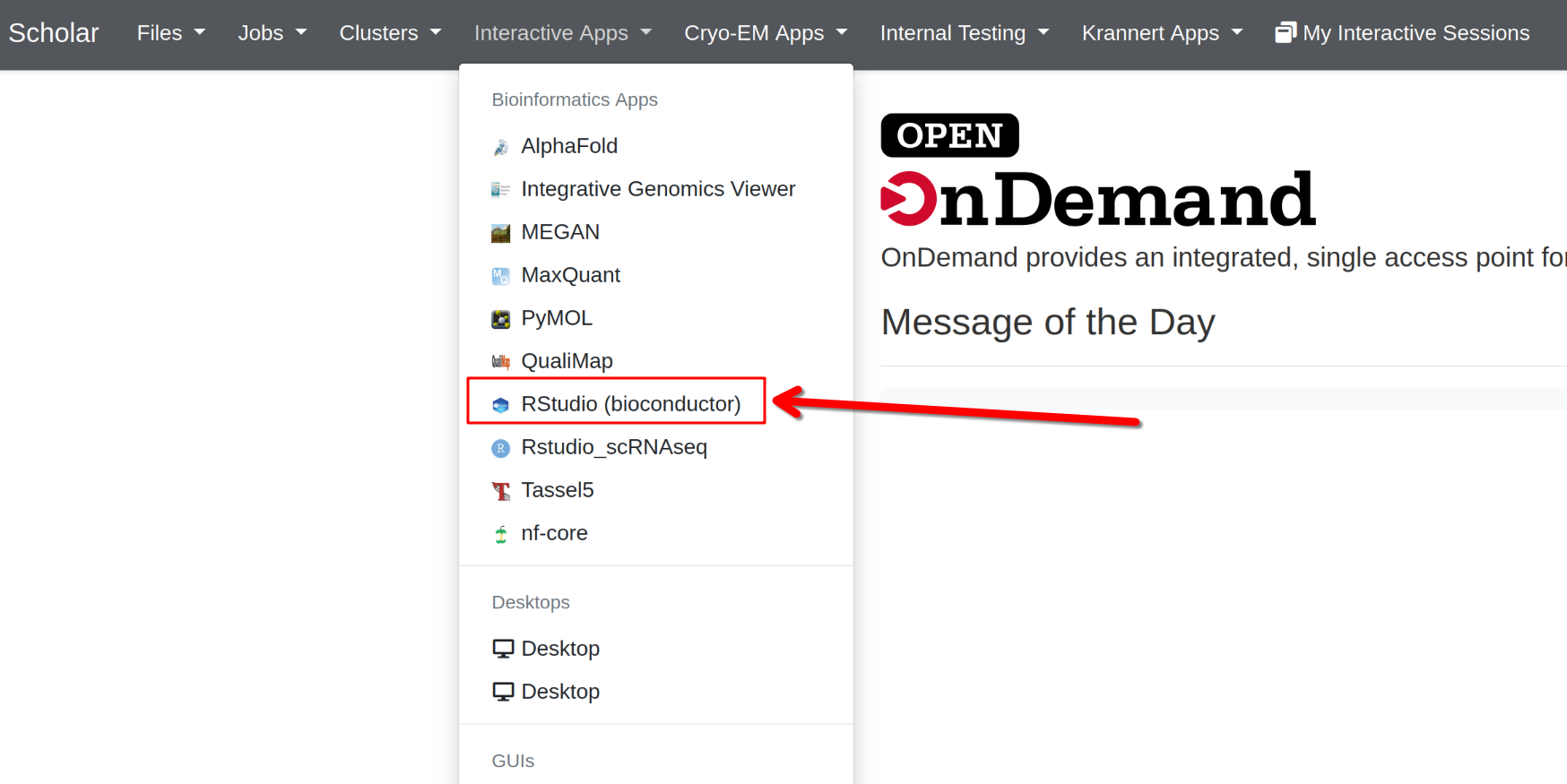
Once in RStudio, load the necessary libraries:
Setup: load packages and data
R
library(RColorBrewer)
library(EnsDb.Mmusculus.v79)
library(ensembldb)
library(tidyverse)
library(DESeq2)
library(ggplot2)
library(pheatmap)
library(readr)
library(dplyr)
library(ComplexHeatmap)
library(ggrepel)
library(vsn)
# Construct the path dynamically
work_dir <- file.path("/scratch/negishi", Sys.getenv("USER"), "rnaseq-workshop")
setwd(work_dir)
countsFile <- "results/counts/gene_counts_clean.txt"
# prepare this file first!
groupFile <- "scripts/samples.csv"
coldata <-
read.csv(
groupFile,
row.names = 1,
header = TRUE,
stringsAsFactors = TRUE
)
coldata$condition <- as.factor(coldata$condition)
cts <- as.matrix(read.delim(countsFile, row.names = 1, header = TRUE))
We also load gene level annotation tables prepared earlier.
R
mart <-
read.csv(
"data/mart.tsv",
sep = "\t",
header = TRUE
)
annot <-
read.csv(
"data/annot.tsv",
sep = "\t",
header = TRUE
)
Since the gene IDs in the count matrix are Ensembl IDs, it will be
hard to interpret the results without annotation. We will need to use
the org.Mm.eg.db package for attaching gene symbols, so we
can interpret the results better.0
R
library(biomaRt)
library(tidyverse)
# select Mart
ensembl = useMart("ENSEMBL_MART_ENSEMBL")
# we need to use the correct dataset for mouse
# we will query the available datasets and filter for mouse (GRCm39)
listDatasets(ensembl) %>%
filter(str_detect(description, "GRCm39"))
# we can use the dataset name to set the dataset
ensembl = useDataset("mmusculus_gene_ensembl", mart = ensembl)
# our counts have Ensembl gene IDs with version numbers
# lets find how it is referred in biomaRt
listFilters(ensembl) %>%
filter(str_detect(name, "ensembl"))
# so we will now set the filter type accordingly
filterType <- "ensembl_gene_id_version"
# from our counts data, get the list of gene IDs
filterValues <- rownames(counts)
# take a look at the available attributes (first 20)
listAttributes(ensembl) %>%
head(20)
# we will retrieve ensembl gene id, ensembl gene id with version and external gene name
attributeNames <- c('ensembl_gene_id',
'ensembl_gene_id_version',
'external_gene_name',
'gene_biotype',
'description')
# get the annotation
annot <- getBM(
attributes = attributeNames,
filters = filterType,
values = filterValues,
mart = ensembl
)
saveRDS(annot, file = "results/counts/gene_annotation.rds")
# also save as tsv for future use
write.table(
annot,
file = "data/mart.tsv",
sep = "\t",
quote = FALSE,
row.names = FALSE
)
# save a simplified annotation file with only essential columns
mart %>%
select(ensembl_gene_id, ensembl_gene_id_version, external_gene_name) %>%
write.table(
file = "data/annot.tsv",
sep = "\t",
quote = FALSE,
row.names = FALSEThe objects loaded here form the foundation for the entire workflow.
cts contains raw gene counts from featureCounts.
coldata contains the metadata that describes each sample
and defines the comparison groups. mart and
annot contain functional information for each gene so we
can attach gene symbols and biotypes later in the analysis.
Sample metadata and design
coldata must have row names that match the count matrix
column names. The condition column defines the groups for
DESeq2 (WT_mock vs WT_IR).
Exploratory analysis
Attach annotation and filter to protein coding genes
We first join counts with biotype information from mart
and filter to protein coding genes.
R
cts_tbl <- cts %>%
as.data.frame() %>%
rownames_to_column("ensembl_gene_id_version")
cts_annot <- cts_tbl %>%
left_join(mart, by = "ensembl_gene_id_version")
sum(is.na(cts_annot$gene_biotype))
Output:
[1] 0Joining annotation allows us to move beyond raw Ensembl IDs. This step attaches gene symbols, biotypes, and descriptions so that later plots and tables are interpretable. At this point the dataset is still large and includes many noncoding genes, pseudogenes, and biotypes we won’t analyze further.
Summarize gene biotypes:
R
biotype_df <- cts_annot %>%
filter(rowSums(select(., starts_with("WT_Bcell"))) > 10) %>%
dplyr::count(gene_biotype, name = "n") %>%
arrange(desc(n))
ggplot(biotype_df, aes(x = reorder(gene_biotype, n), y = n)) +
geom_col(fill = "steelblue") +
coord_flip() +
theme_minimal() +
labs(
x = "Gene biotype",
y = "Number of genes",
title = "Distribution of expressed gene biotypes (Total Counts > 10)"
)
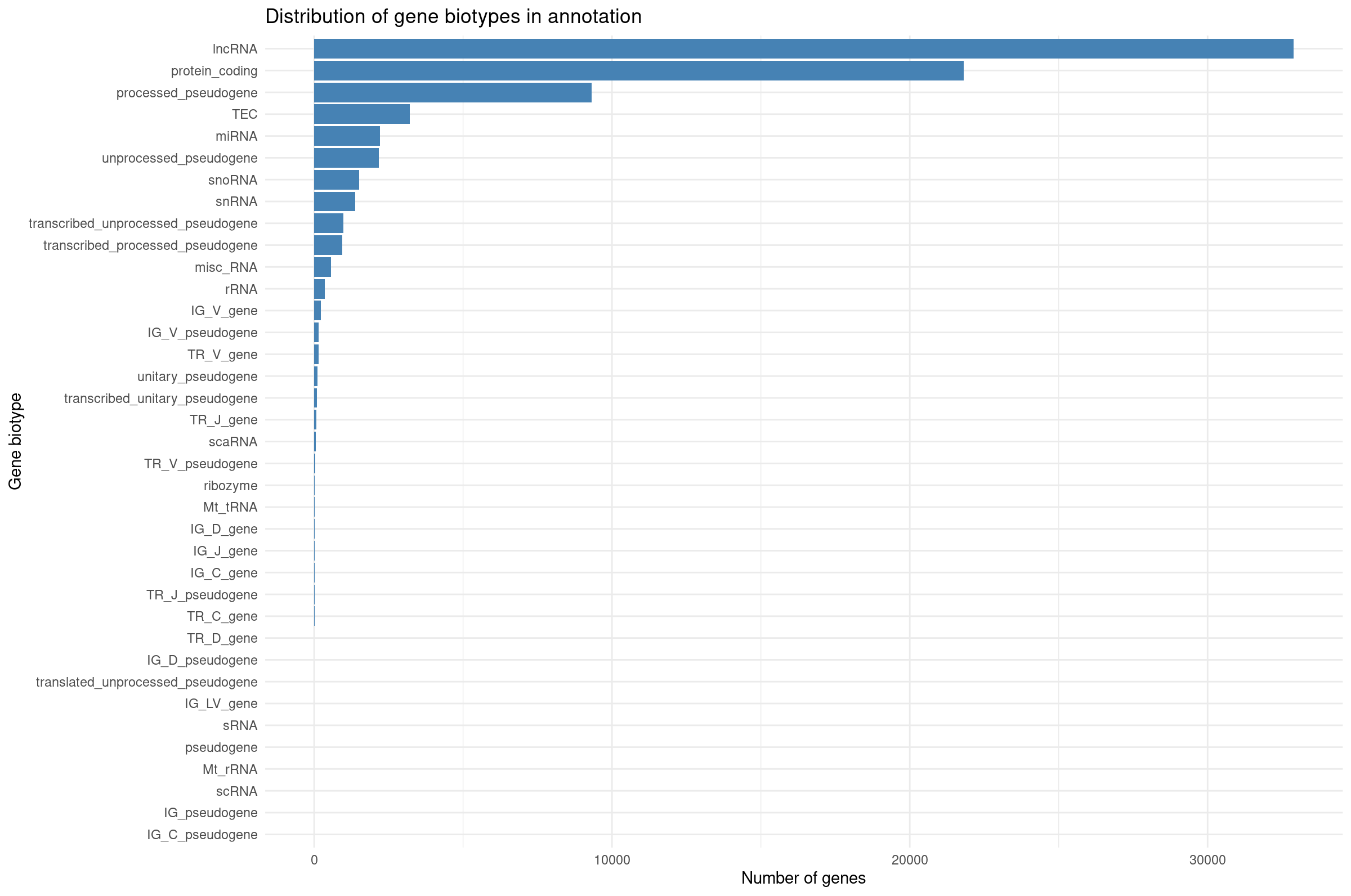
Visualizing biotype composition gives a sense of how many genes belong to each functional class. RNA-seq quantifies all transcribed loci, but many biotypes (snRNA, TEC, pseudogenes) are not suitable for differential expression with DESeq2 because they tend to be lowly expressed or unstable. This motivates filtering to protein-coding genes for QC and visualization.
Filter to protein coding genes and apply group-aware expression filtering:
R
# Filter to protein-coding genes
cts_pc <- cts_annot %>%
filter(gene_biotype == "protein_coding") %>%
dplyr::select(ensembl_gene_id_version, all_of(rownames(coldata)))
# Group-aware filtering: keep genes with >= 10 counts in at least 4 samples
# (the size of the smallest experimental group)
min_samples <- 4
min_counts <- 10
cts_coding <- cts_pc %>%
filter(rowSums(across(all_of(rownames(coldata)), ~ . >= min_counts)) >= min_samples) %>%
column_to_rownames("ensembl_gene_id_version")
dim(cts_coding)
[1] 11330 8Why use group-aware filtering?
A simple sum filter (e.g., rowSums > 5) can be
problematic:
- A gene with 10 total counts across 8 samples averages ~1.25 counts/sample—often too noisy.
- It may inadvertently remove genes expressed in only one condition.
Group-aware filtering ensures:
- Each kept gene has meaningful expression in at least one experimental group.
- Genes with condition-specific expression are retained.
- The threshold is interpretable (“at least 10 counts in at least 4 samples”).
For exploratory analysis, we also restrict to protein-coding genes to focus on the most interpretable features.
Library size differences
We summarize total counts per sample for protein coding genes.
R
libSize <- colSums(cts_coding) %>%
as.data.frame() %>%
rownames_to_column("sample") %>%
rename(total_counts = 2) %>%
mutate(total_millions = total_counts / 1e6)
ggplot(libSize, aes(x = sample, y = total_counts)) +
geom_col(fill = "steelblue") +
theme_minimal() +
labs(
x = "Sample",
y = "Total assigned reads",
title = "Total reads per sample"
) +
theme(
axis.text.x = element_text(angle = 45, hjust = 1)
)
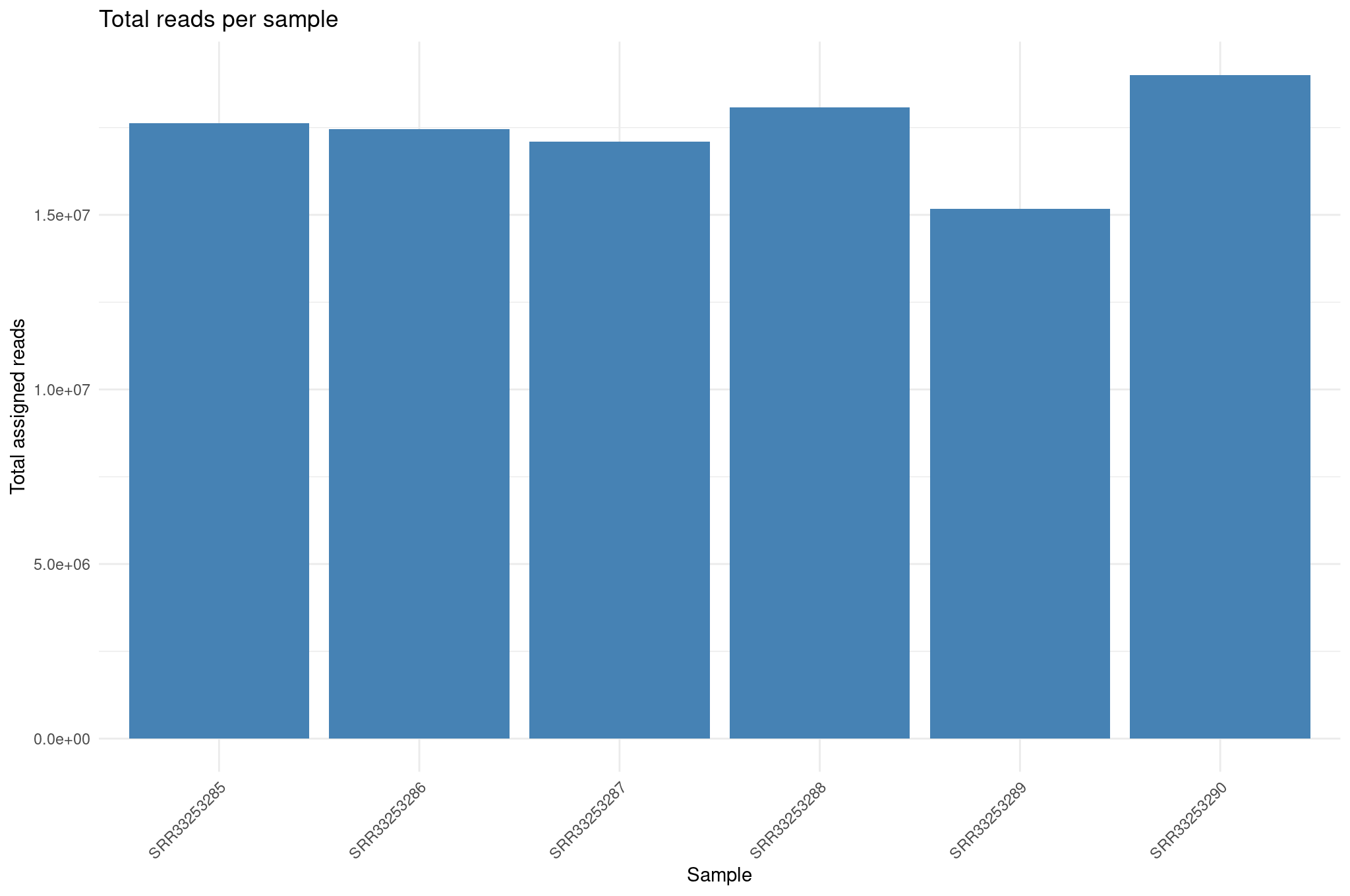
Library size differences affect normalization. Although DESeq2 corrects for this through size factors, inspecting raw library sizes ensures no sample has abnormally low sequencing depth, which could compromise downstream analyses.
Create DESeq2 object for exploratory plots
R
dds <- DESeqDataSetFromMatrix(
countData = cts_coding,
colData = coldata,
design = ~ condition
)
dds <- estimateSizeFactors(dds)
Inspect size factors vs library size:
R
ggplot(
data.frame(
libSize = colSums(assay(dds)),
sizeFactor = sizeFactors(dds),
Group = dds$condition
),
aes(x = libSize, y = sizeFactor, col = Group)
) +
geom_point(size = 5) +
theme_bw() +
labs(x = "Library size", y = "Size factor")
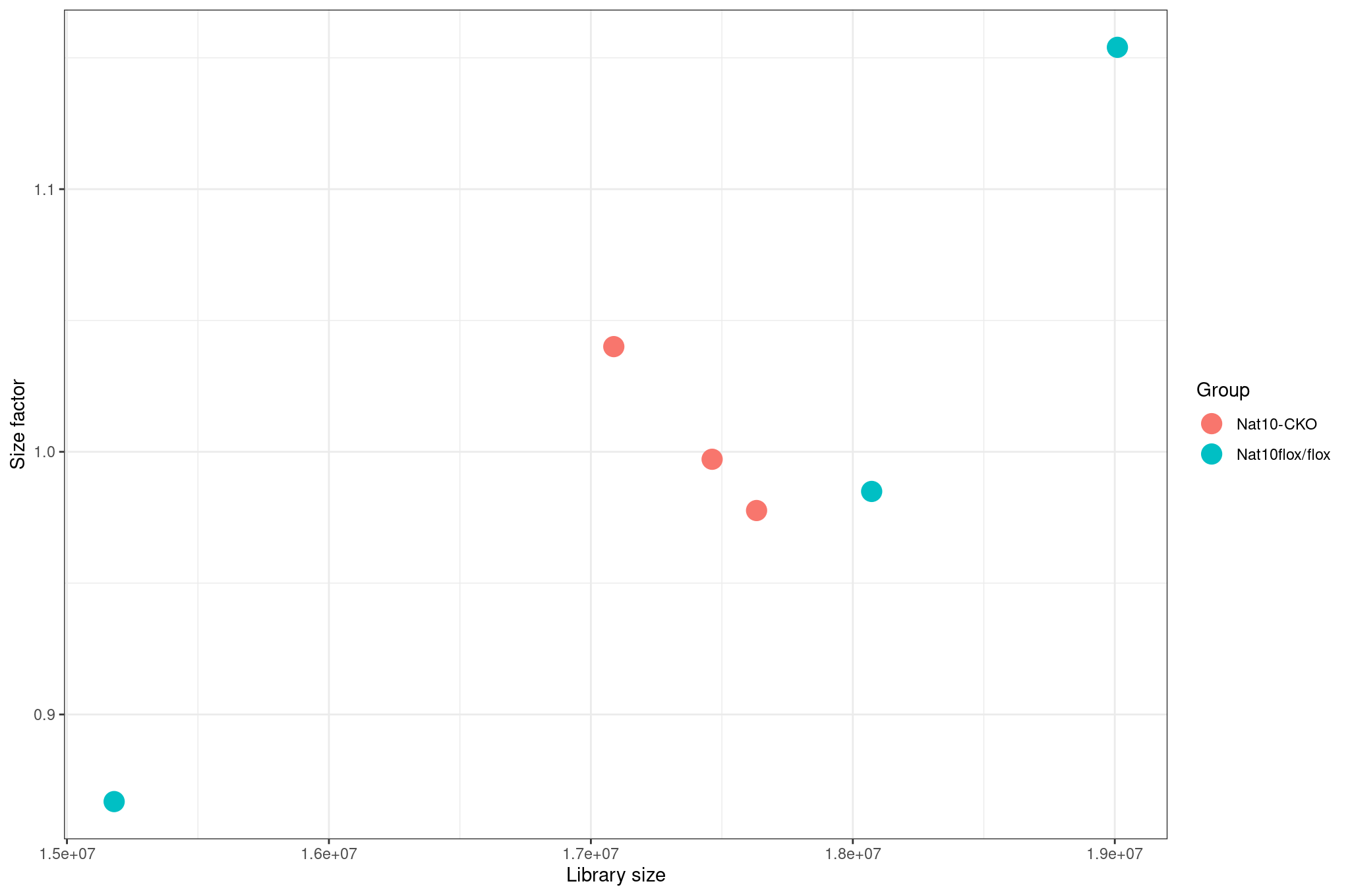
Variance stabilization and mean SD plots
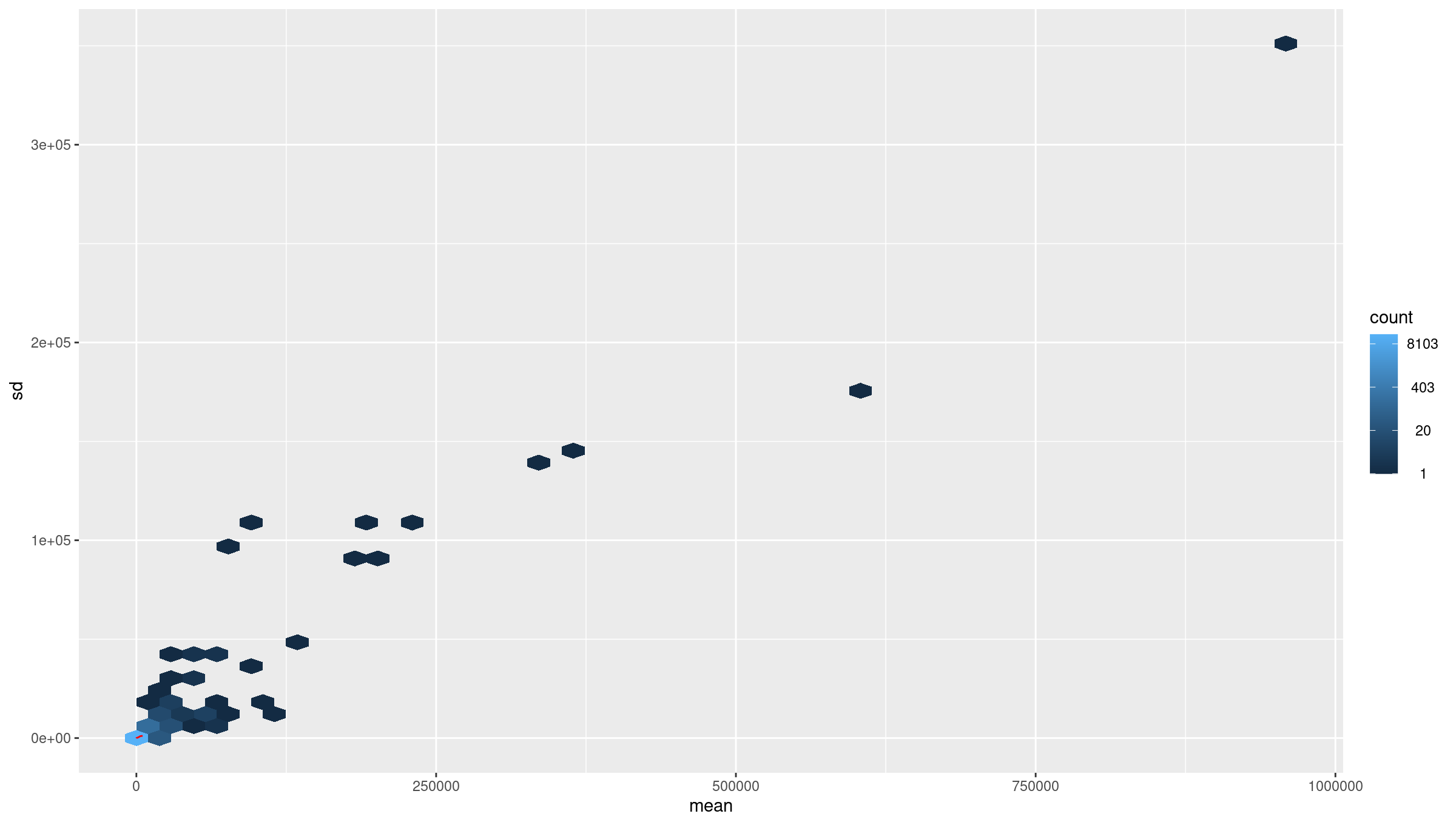
Raw count data have a strong mean–variance dependency: low count genes have high variance, and high count genes show lower relative variability. This makes Euclidean distance and PCA misleading on raw counts. VST removes this dependency so that downstream clustering is biologically meaningful rather than driven by count scale.
Inspect mean vs standard deviation plot before transformation:
R
meanSdPlot(assay(dds), ranks = FALSE)
Apply variance stabilizing transform (VST):
R
vsd <- DESeq2::vst(dds, blind = TRUE)
meanSdPlot(assay(vsd), ranks = FALSE)
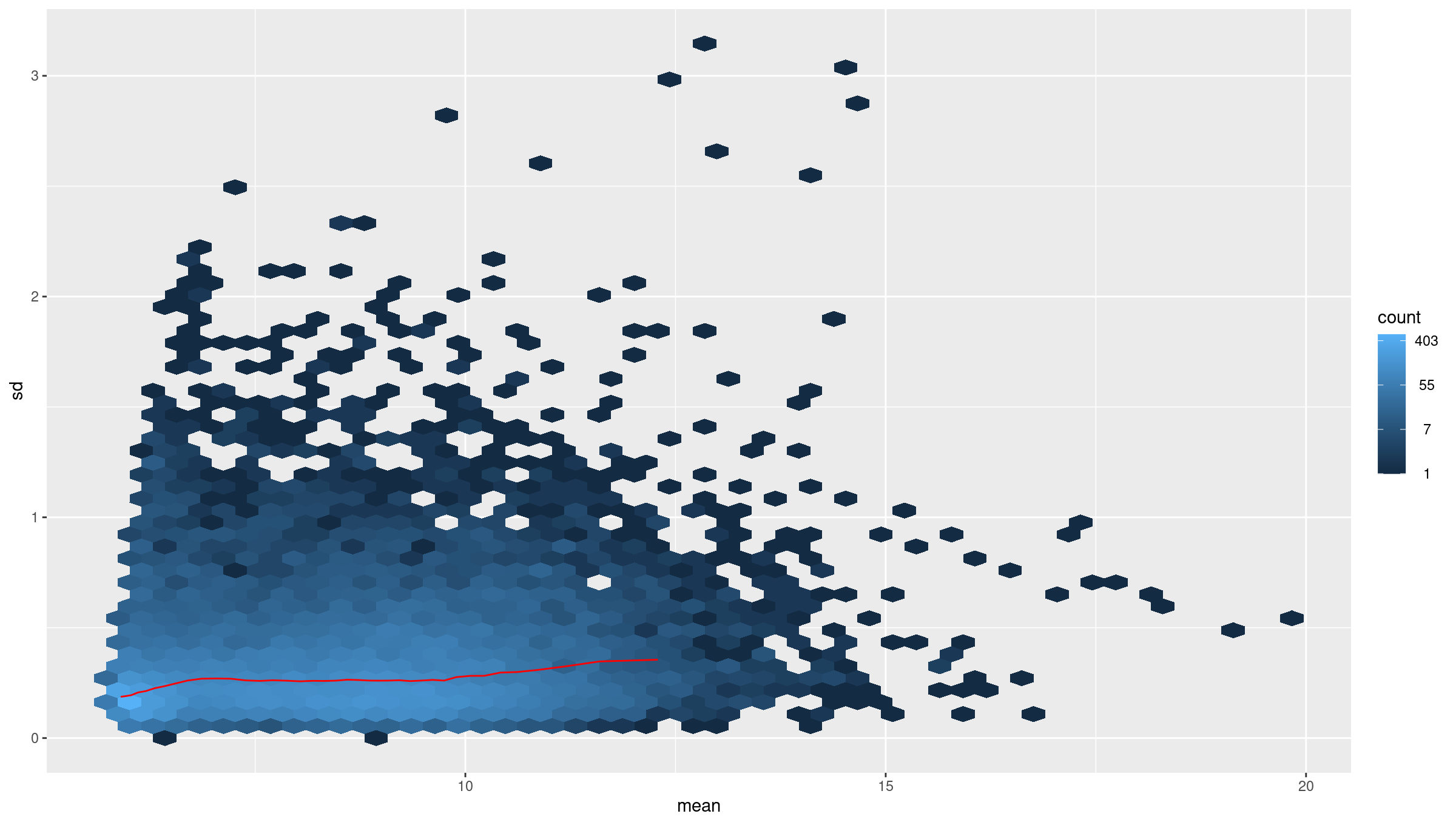
Why use VST
Counts have mean dependent variance. Variance stabilizing transform (VST) makes the variance roughly constant across the range, which improves distance based methods and PCA.
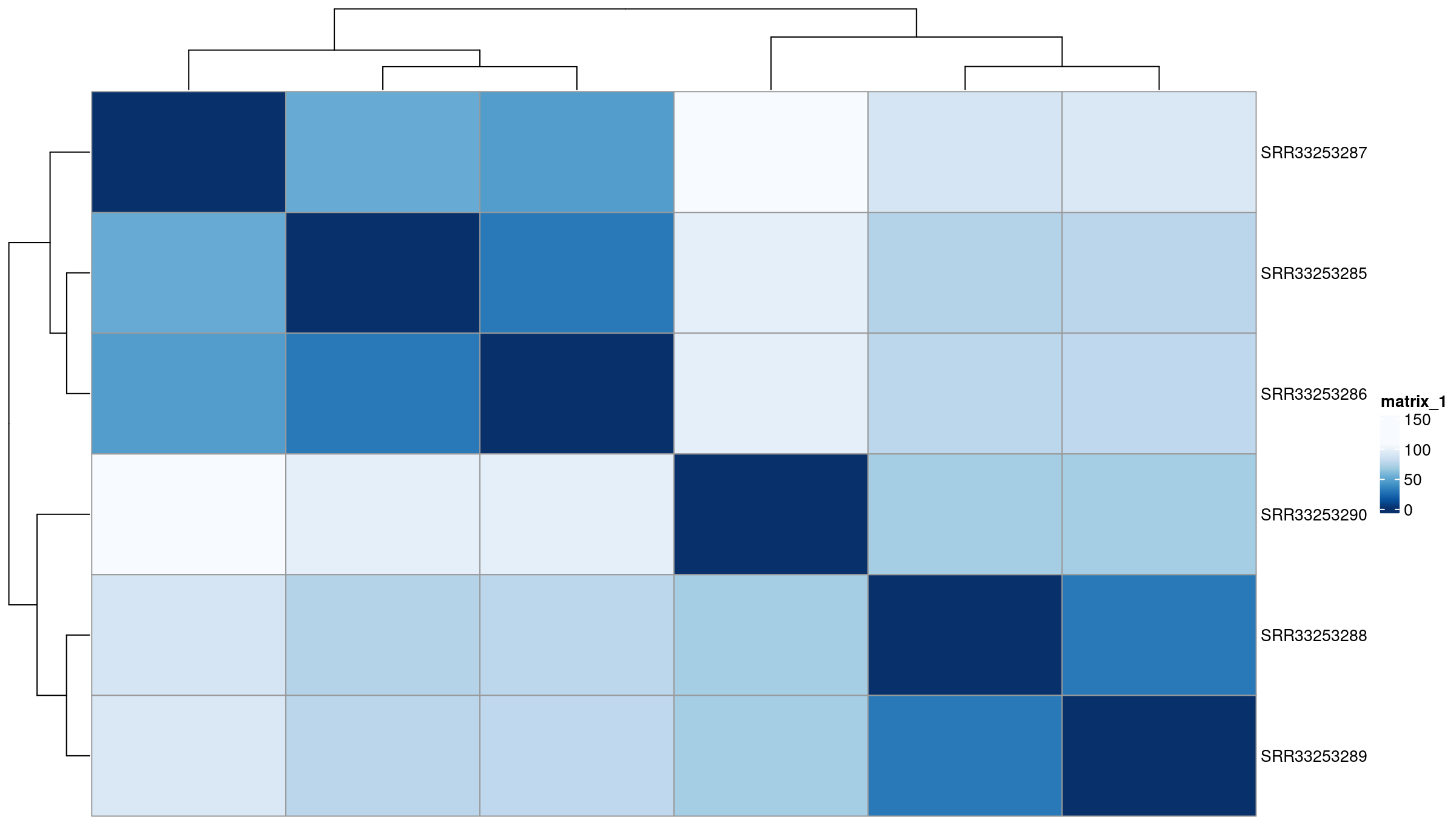
Sample to sample distances
The distance heatmap helps answer a key question: Do samples group by biological condition or by an unwanted variable (batch, sequencing run, contamination)? This is one of the fastest ways to detect outliers.
R
sampleDists <- dist(t(assay(vsd)))
sampleDistMatrix <- as.matrix(sampleDists)
rownames(sampleDistMatrix) <- colnames(vsd)
colnames(sampleDistMatrix) <- NULL
colors <- colorRampPalette(rev(brewer.pal(9, "Blues")))(255)
pheatmap(
sampleDistMatrix,
clustering_distance_rows = sampleDists,
clustering_distance_cols = sampleDists,
col = colors
)
PCA on top variable genes
PCA projects samples into low-dimensional space and reveals dominant sources of variation. Ideally, samples separate by biological condition along one of the top PCs. If not, the signal from the condition may be weak or confounded by other factors.
R
rv <- rowVars(assay(vsd))
select <- order(rv, decreasing = TRUE)[seq_len(min(500, length(rv)))]
pca <- prcomp(t(assay(vsd)[select, ]))
percentVar <- pca$sdev ^ 2 / sum(pca$sdev ^ 2)
intgroup <- "condition"
intgroup.df <- as.data.frame(colData(vsd)[, intgroup, drop = FALSE])
group <- if (length(intgroup) == 1) {
factor(apply(intgroup.df, 1, paste, collapse = " : "))
}
d <- data.frame(
PC1 = pca$x[, 1],
PC2 = pca$x[, 2],
intgroup.df,
name = colnames(vsd)
)
ggplot(d, aes(PC1, PC2, color = condition)) +
scale_shape_manual(values = 1:12) +
scale_color_manual(values = c(
"WT_mock" = "#00b462",
"WT_IR" = "#980c80"
)) +
theme_bw() +
theme(legend.title = element_blank()) +
geom_point(size = 2, stroke = 2) +
geom_text_repel(aes(label = name)) +
xlab(paste("PC1", round(percentVar[1] * 100, 2), "% variance")) +
ylab(paste("PC2", round(percentVar[2] * 100, 2), "% variance"))
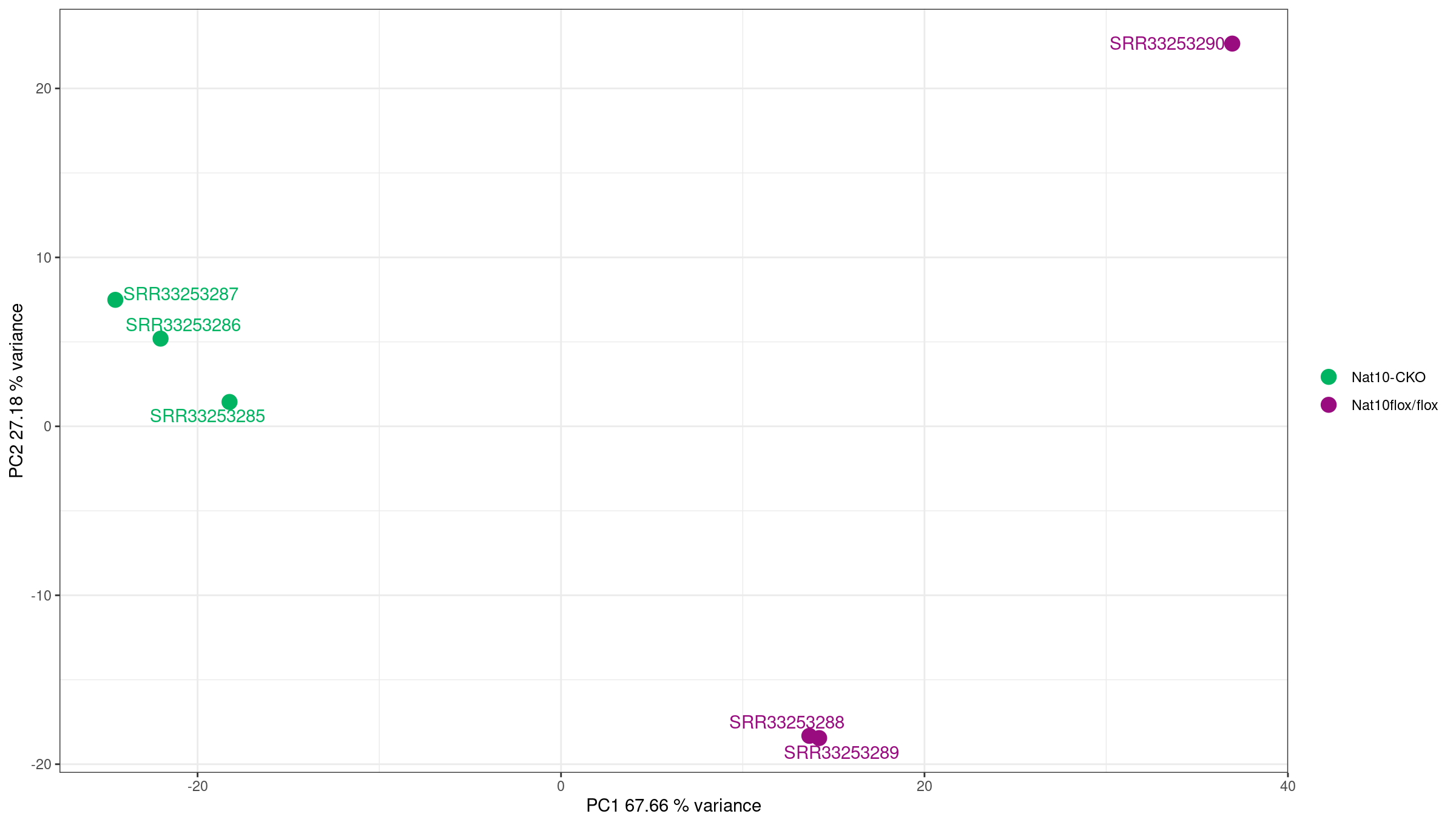
Using PCA to detect batch effects
PCA is one of the most powerful tools for detecting batch effects—unwanted technical variation from sample processing, sequencing runs, or other non-biological factors.
What to look for:
- Good: Samples separate primarily by biological condition (treatment, genotype).
- Concerning: Samples cluster by processing date, sequencing lane, or technician instead of biology.
- Red flag: PC1 captures technical variation rather than the condition of interest.
If you detect batch effects:
-
Include batch in the design formula if batch is known:
R
design = ~ batch + condition Use batch correction tools like
ComBat-seqorsvafor complex batch structures.Never simply remove batch-affected samples without understanding the underlying cause.
In this dataset, samples cluster cleanly by condition, indicating no obvious batch effects.
Exercise: interpret exploratory plots
Using the library size, distance heatmap, and PCA:
- Are there any obvious outlier samples?
- Do replicates from the same condition cluster together?
- Does any sample look inconsistent with its metadata label?
- Is there evidence of batch effects (samples clustering by non-biological factors)?
Example interpretation:
- Library sizes are comparable across samples and fall within a narrow range.
- Samples cluster by condition (mock vs IR-treated) in both distance heatmaps and PCA.
- No sample appears as a clear outlier relative to its group.
- No batch effects are apparent—PC1 separates by experimental condition, not technical factors.
Differential gene expression analysis
For DE testing we use the full count matrix
(cts) without filtering by biotype. This preserves all
features counted by featureCounts.
R
dds <- DESeqDataSetFromMatrix(
countData = cts_coding,
colData = coldata,
design = ~ condition
)
You can either run the individual DESeq2 steps:
R
dds <- estimateSizeFactors(dds)
dds <- estimateDispersions(dds)
dds <- nbinomWaldTest(dds)
Above three steps can be run together using the DESeq
function:
R
dds <- DESeq(dds)
estimating size factors
Note: levels of factors in the design contain characters other than
letters, numbers, '_' and '.'. It is recommended (but not required) to use
only letters, numbers, and delimiters '_' or '.', as these are safe characters
for column names in R. [This is a message, not a warning or an error]
estimating dispersions
gene-wise dispersion estimates
mean-dispersion relationship
Note: levels of factors in the design contain characters other than
letters, numbers, '_' and '.'. It is recommended (but not required) to use
only letters, numbers, and delimiters '_' or '.', as these are safe characters
for column names in R. [This is a message, not a warning or an error]
final dispersion estimates
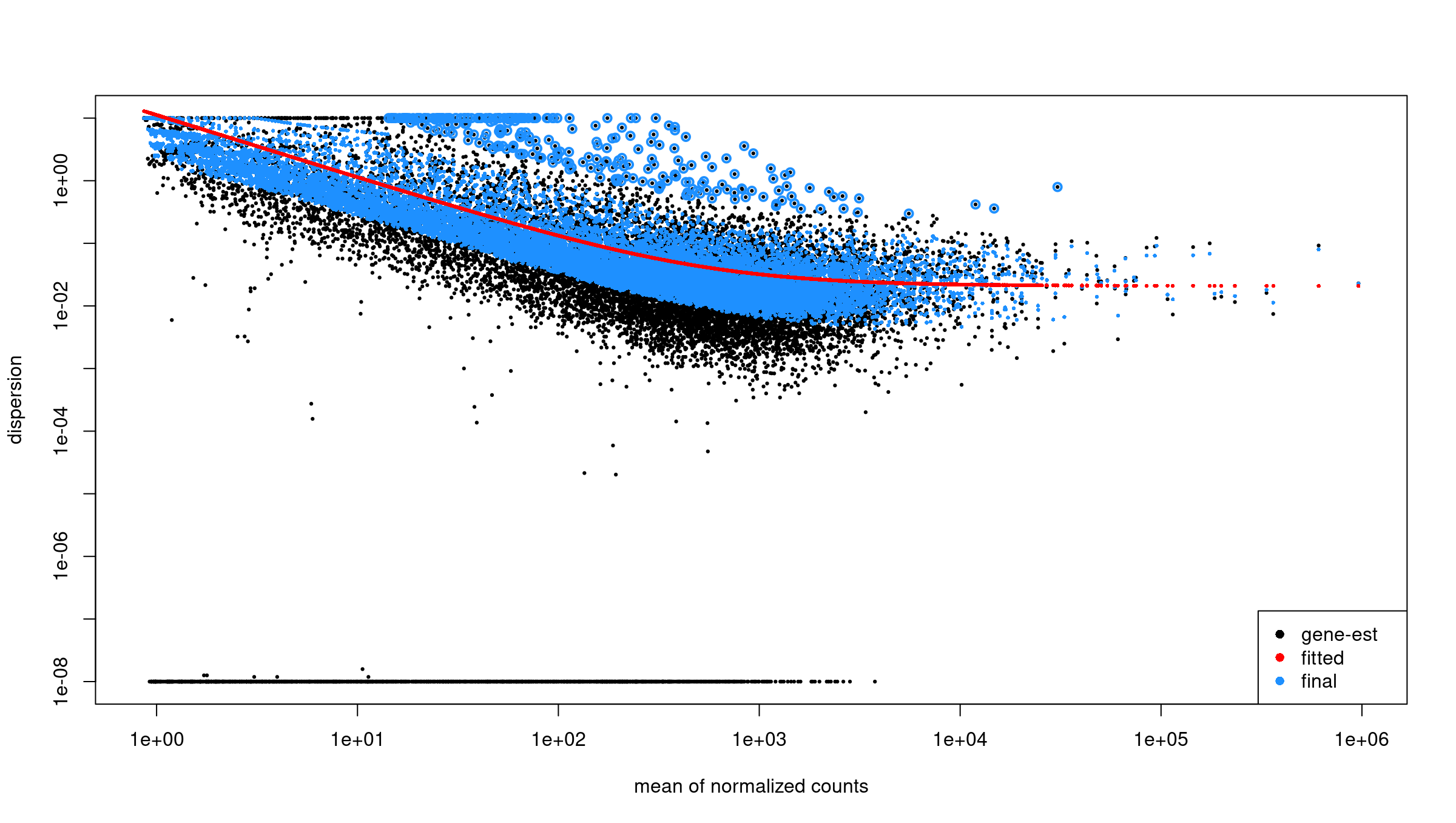
fitting model and testingInspect dispersion estimates:
R
plotDispEsts(dds)
Obtain results for the contrast of interest (WT_IR vs
WT_mock):
R
res <-
results(
dds,
contrast = c(
"condition",
"WT_IR",
"WT_mock"
)
)
summary(res)
TXT
out of 11330 with nonzero total read count
adjusted p-value < 0.1
LFC > 0 (up) : 3317, 29%
LFC < 0 (down) : 3260, 29%
outliers [1] : 0, 0%
low counts [2] : 0, 0%
(mean count < 7)
[1] see 'cooksCutoff' argument of ?results
[2] see 'independentFiltering' argument of ?resultsOrder the results by p value to see the top DE genes:
R
head(res[order(res$pvalue), ])
log2 fold change (MLE): condition WT_IR vs WT_mock
Wald test p-value: condition WT_IR vs WT_mock
DataFrame with 6 rows and 6 columns
baseMean log2FoldChange lfcSE stat pvalue padj
<numeric> <numeric> <numeric> <numeric> <numeric> <numeric>
ENSMUSG00000026581.15 2412.406 -2.80863 0.0812517 -34.5671 7.89898e-262 8.94955e-258
ENSMUSG00000021668.16 869.712 3.75461 0.1109288 33.8470 4.01308e-251 2.27341e-247
ENSMUSG00000075122.6 614.418 4.47065 0.1336974 33.4386 3.77523e-245 1.42578e-241
ENSMUSG00000004085.15 833.506 4.21081 0.1293034 32.5654 1.26916e-232 3.59488e-229
ENSMUSG00000020184.16 1619.577 2.82923 0.0906311 31.2170 6.26193e-214 1.41895e-210
ENSMUSG00000072825.13 724.296 4.73072 0.1518464 31.1546 4.39181e-213 8.29321e-210Each row represents one gene. Key columns: baseMean:
average normalized count across all samples log2FoldChange:
direction and magnitude of change between groups pvalue /
padj: statistical significance after multiple testing
correction Genes with NA values often have too few reads to
estimate dispersion and should not be interpreted.
Apply log fold change shrinkage
The raw log2 fold change estimates from DESeq2 can be noisy for genes with low counts. Shrinkage improves these estimates.
First, check the available coefficient names:
R
resultsNames(dds)
[1] "Intercept" "condition_WT_mock_vs_WT_IR"Apply shrinkage using apeglm (recommended for standard
two-group comparisons):
R
res_shrunk <- lfcShrink(
dds,
coef = "condition_WT_mock_vs_WT_IR",
type = "apeglm"
)
summary(res_shrunk)
out of 11330 with nonzero total read count
adjusted p-value < 0.1
LFC > 0 (up) : 3260, 29%
LFC < 0 (down) : 3317, 29%
outliers [1] : 0, 0%
low counts [2] : 0, 0%
(mean count < 7)
[1] see 'cooksCutoff' argument of ?results
[2] see 'independentFiltering' argument of ?resultsWhy shrink log fold changes?
Genes with low counts can have unreliably large fold changes. Shrinkage:
- Reduces noise in LFC estimates for lowly-expressed genes.
- Improves gene ranking for downstream analyses (e.g., GSEA).
- Does not affect p-values or significance calls.
Choosing a shrinkage method:
-
apeglm(recommended): Fast, well-calibrated, uses coefficient name (coef). -
ashr: Required for complex contrasts that can’t be specified withcoef. -
normal: Legacy method, generally not recommended.
For downstream analyses, we’ll use the shrunken results:
R
res <- res_shrunk
Create a summary table:
R
log2fc_cut <- log2(1.5)
res_df <- as.data.frame(res)
summary_table <- tibble(
total_genes = nrow(res_df),
sig = sum(res_df$padj < 0.05, na.rm = TRUE),
up = sum(res_df$padj < 0.05 & res_df$log2FoldChange > log2fc_cut, na.rm = TRUE),
down= sum(res_df$padj < 0.05 & res_df$log2FoldChange < -log2fc_cut, na.rm = TRUE)
)
print(summary_table)
Output:
# A tibble: 1 × 4
total_genes sig up down
<int> <int> <int> <int>
1 11330 5967 1802 1795Keep gene IDs:
R
res_df <- as.data.frame(res)
res_df$ensembl_gene_id_version <- rownames(res_df)
Joining results with expression and annotation
Get normalized counts:
R
norm_counts <- counts(dds, normalized = TRUE)
norm_counts_df <- as.data.frame(norm_counts)
norm_counts_df$ensembl_gene_id_version <- rownames(norm_counts_df)
Join DE results, normalized counts, and annotation:
R
res_annot <- res_df %>%
dplyr::left_join(norm_counts_df,
by = "ensembl_gene_id_version") %>%
dplyr::left_join(mart,
by = "ensembl_gene_id_version")
Joining normalized counts and annotation makes the output
biologically interpretable. The final table becomes a comprehensive
results object containing: - gene identifiers -
gene symbols - functional descriptions -
differential expression statistics -
normalized expression values This is the format most
researchers expect when examining results or importing them into
downstream tools.
Define significance labels for plotting:
R
log2fc_cut <- log2(1.5)
res_annot <- res_annot %>%
dplyr::mutate(
label = dplyr::coalesce(external_gene_name, ensembl_gene_id_version),
sig = dplyr::case_when(
padj <= 0.05 & log2FoldChange >= log2fc_cut ~ "up",
padj <= 0.05 & log2FoldChange <= -log2fc_cut ~ "down",
TRUE ~ "ns"
)
)
Visualization: volcano plot
The volcano plot summarizes statistical significance
(padj) and effect size (log2FoldChange)
simultaneously. Genes far left or right show strong expression
differences. Genes high on the plot pass stringent significance
thresholds. Labels help identify the most biologically meaningful
genes.
R
ggplot(
res_annot,
aes(
x = log2FoldChange,
y = -log10(padj),
col = sig,
label = label
)
) +
geom_point(alpha = 0.6) +
scale_color_manual(values = c(
"up" = "firebrick",
"down" = "dodgerblue3",
"ns" = "grey70"
)) +
geom_text_repel(
data = dplyr::filter(res_annot, sig != "ns"),
max.overlaps = 12,
min.segment.length = Inf,
box.padding = 0.3,
seed = 42,
show.legend = FALSE
) +
theme_classic() +
xlab("log2 fold change") +
ylab("-log10 adjusted p value") +
ggtitle("Volcano plot: WT_IR vs WT_mock")
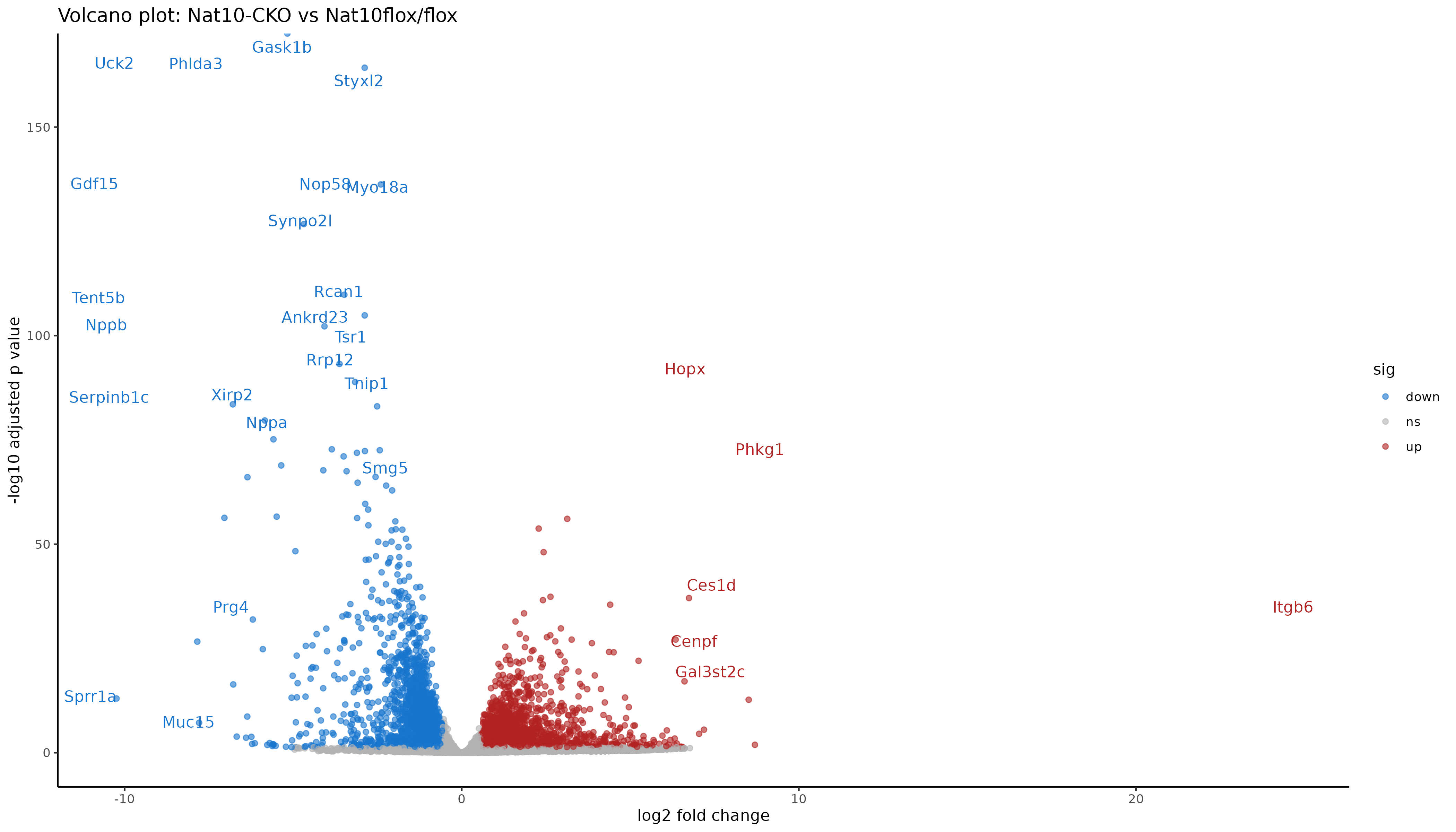
Interpreting the volcano
Points to the right are higher in IR-treated samples (upregulated by radiation), to the left are higher in mock (downregulated by radiation). Points near the top have stronger statistical support (small adjusted p values). Colored points mark genes that pass both fold change and padj thresholds.
Saving results
Saving both the full table and the significant subset allows flexibility: - The full table is needed for pathway analyses and reproducibility. - The subset table focuses on interpretable and biologically meaningful DE genes.
R
readr::write_tsv(
res_annot,
"results/deseq2/DESeq2_results_joined.tsv"
)
Filter to significant genes (padj ≤ 0.05 and fold change ≥ 1.5):
R
sig_res <- res_annot %>%
dplyr::filter(
padj <= 0.05,
abs(log2FoldChange) >= log2fc_cut
)
readr::write_tsv(
sig_res,
"results/deseq2/DESeq2_results_sig.tsv"
)
Save the DESeq2 object for downstream analysis:
R
saveRDS(dds, "results/deseq2_results/dds_featurecounts.rds")
Exercise: explore top DE genes
Using sig_res:
- Which genes have the largest positive log2 fold change.
- Which genes have the largest negative log2 fold change.
- Are any of the top genes known p53 targets or DNA damage response genes.
Example interpretation:
- Strongly upregulated genes should include canonical p53 targets such as Cdkn1a (p21), Mdm2, Bax, and Bbc3 (Puma).
- DNA damage response genes like Gadd45a should be upregulated.
- Cross-referencing top hits with p53 target databases confirms our analysis is working correctly.
Summary
- Counts and sample metadata must be aligned before building DESeq2 objects.
- Biotype annotation allows restriction to protein coding genes for exploratory QC.
- Variance stabilizing transform, distance heatmaps, and PCA help detect outliers and batch effects.
- DESeq2 provides a complete pipeline from raw counts to differential expression.
- Joining DE results with normalized counts and gene annotation yields a useful final table.
- Volcano plots summarize differential expression using fold change and adjusted p values.